| Key Words: sample size calculation, medical research sample size, clinical study power analysis, PASS sample size, G*Power medical statistics |
| A practical guide for clinical researchers on sample size calculation for medical research: a practical guide before data collection, including assumptions, common mistakes, reporting language, and manuscript-ready interpretation. |
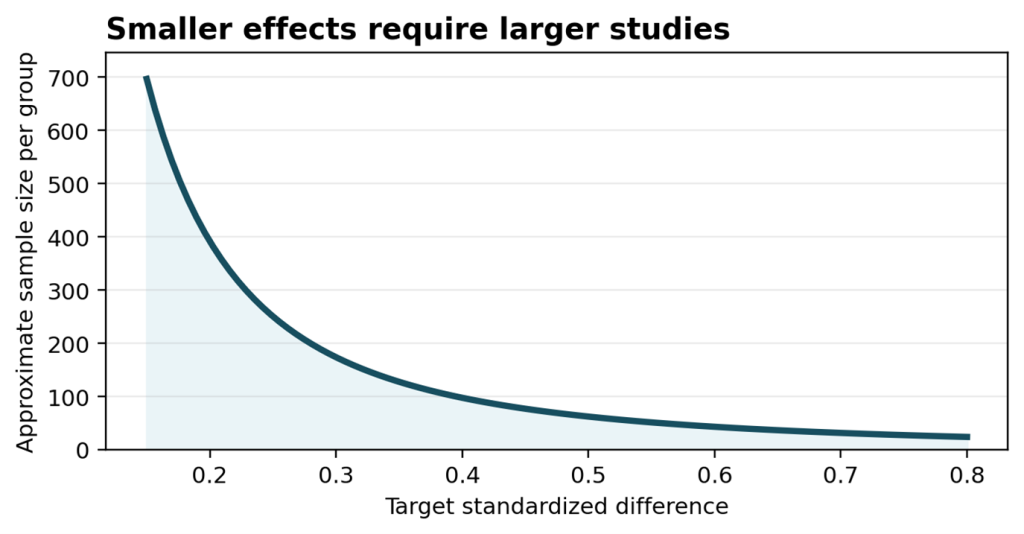
Figure 1. In most comparative studies, a smaller expected effect requires a larger sample size.
Why this topic matters
Sample size calculation is one of the first statistical questions a medical researcher should answer. It is also one of the most common reasons why a study protocol, ethics application, or manuscript receives statistical comments. A study with too few participants may miss a clinically meaningful effect; a study with unnecessarily large recruitment may waste time, funding, and patient resources.
A good sample size calculation is not a software exercise only. It is a short scientific argument: what outcome will be measured, what difference is clinically meaningful, how much variability is expected, and what level of uncertainty is acceptable? Once these assumptions are clear, tools such as PASS, G*Power, R, Stata, or SPSS add-on procedures become much easier to use.
Start with the research question, not the software
Before opening any sample size software, define the primary objective in one sentence. For example: “This study compares the mean 12-week HbA1c reduction between two treatment groups.” This sentence already contains several key elements: the outcome is continuous, the design is two-group comparison, the main estimate is a mean difference, and the time point is fixed.
For diagnostic, survival, or prediction studies, the structure is different. A diagnostic accuracy study may focus on sensitivity, specificity, or AUC. A survival study depends on the number of events, follow-up duration, and censoring. A prediction model requires enough outcome events and sufficient information to avoid overfitting. The sample size formula changes because the estimand changes.
Essential inputs for most sample size calculations
Most calculations require four practical inputs. First, choose the primary outcome. Second, define the clinically meaningful effect size, such as a difference in means, difference in proportions, hazard ratio, odds ratio, or AUC target. Third, provide variability or baseline event rate from previous studies, pilot data, or credible clinical assumptions. Fourth, choose type I error and power, commonly two-sided alpha of 0.05 and power of 80% or 90%.
When assumptions are uncertain, do not hide the uncertainty. Present a small sensitivity table. For example, show sample sizes under three possible standard deviations or three possible event rates. This makes the planning transparent and prevents the calculation from looking artificially precise.
Common mistakes reviewers notice
Common problems include calculating sample size for a secondary outcome, using an effect size that is statistically convenient but clinically unrealistic, ignoring dropout, using a one-sided test without justification, and reporting only a final number without assumptions. Another frequent issue is mixing different designs: for example, using a simple two-sample formula when the actual study uses repeated measures or matched pairs.
For retrospective studies, authors sometimes write that “sample size calculation was not required.” A better approach is to explain the available sample, the expected precision, or a post hoc detectable effect. Avoid presenting post hoc power as if it validates the study; confidence intervals and precision usually communicate the limitation more clearly.
A practical reporting template
In a protocol or manuscript, the sample size paragraph should be short but complete. A useful template is: “The primary endpoint was [endpoint]. Based on previous data, we expected [assumption]. To detect [effect size] with a two-sided alpha of 0.05 and 80% power, [n] participants per group were required. Assuming [dropout rate] attrition, the target enrollment was [final n]. The calculation was performed using [software/version].”
This paragraph helps reviewers verify the logic without searching through supplementary files. It also shows that the study was designed around a clinically meaningful question rather than a convenient available dataset.
Practical checklist
- Define one primary outcome before calculating sample size.
- Use clinically meaningful effect sizes, not only statistically detectable differences.
- Include expected variability, baseline rate, follow-up time, or event count as appropriate.
- Add dropout or missing-data assumptions.
- Report software, version, alpha, power, and assumptions.
| Professional service note Need a defensible sample size paragraph for a protocol or manuscript? Prepare the study design, primary endpoint, expected effect, and any pilot or literature values before asking for statistical support. |